ML 애플리케이션을 만들 때 “잘 동작하는가?”
만큼 중요한 게 바로 “어떻게 동작하고 있는가?” 입니다.
이번 단계에서는 서비스의 내부 상태를 들여다보기 위한 첫걸음으로,
FastAPI와 Ray Serve의 로그를 로컬에서 직접 관찰(Observability) 해보겠습니다.
우선 복잡한 모니터링 스택(Grafana, Loki, Tempo)을 붙이기 전,
가장 간단한 방식인 uvicorn Log 를 이용한 Local 실습부터 시작합니다.!
이 과정을 통해 App이 요청을 어떻게 처리하고,
어떤 순서로 Log를 남기는지 직접 눈으로 확인할 수 있습니다.
0) 초기화 (이전에 계속 실패했던 ray 깔끔히 정리)
# 포트/프로세스 정리
ray stop --force 2>/dev/null || true
fuser -k 8000/tcp 2>/dev/null || true
fuser -k 8001/tcp 2>/dev/null || true

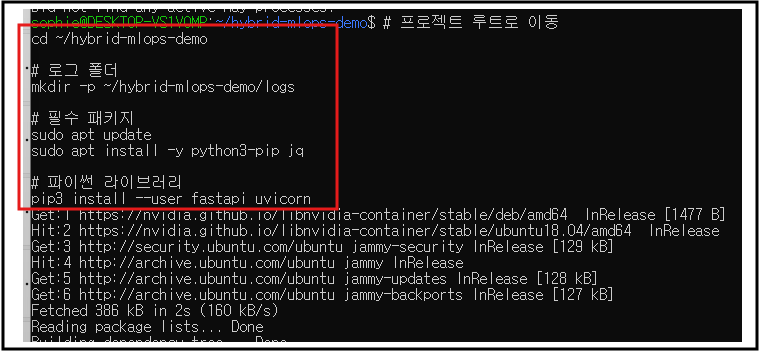
1) 기본 폴더/패키지 준비
# 프로젝트 루트로 이동
cd ~/hybrid-mlops-demo
# 로그 폴더
mkdir -p ~/hybrid-mlops-demo/logs
# 필수 패키지
sudo apt update
sudo apt install -y python3-pip jq
# 파이썬 라이브러리
pip3 install --user fastapi uvicorn
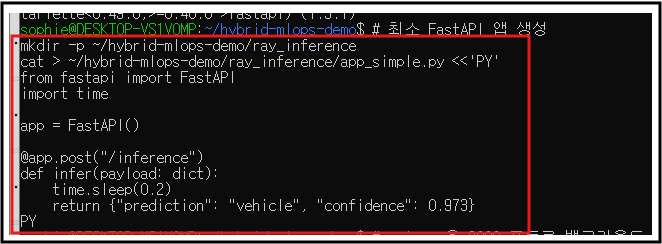
2) “가장 쉬운” FastAPI 앱으로 먼저 성공시키기
# 최소 FastAPI 앱 생성
mkdir -p ~/hybrid-mlops-demo/ray_inference
cat > ~/hybrid-mlops-demo/ray_inference/app_simple.py <<'PY'
from fastapi import FastAPI
import time
app = FastAPI()
@app.post("/inference")
def infer(payload: dict):
time.sleep(0.2)
return {"prediction": "vehicle", "confidence": 0.973}
PY
2-1) 서버를 백그라운드로 실행
# uvicorn을 8000 포트로 백그라운드 실행, 로그 파일로 저장
nohup python3 -m uvicorn ray_inference.app_simple:app --host 127.0.0.1 --port 8000 \\
> ~/hybrid-mlops-demo/logs/inference.log 2>&1 & echo $! > /tmp/uvicorn.pid
# 확인: PID 출력
cat /tmp/uvicorn.pid

2-2) 요청 보내서 동작 확인
curl -sS -X POST <http://127.0.0.1:8000/inference> \\
-H 'Content-Type: application/json' \\
-d '{"image":"frame001.jpg"}' | jq .
예상 출력:
{
"prediction": "vehicle",
"confidence": 0.973
}

2-3) 로그 확인
tail -n 50 -f ~/hybrid-mlops-demo/logs/inference.log
# (로그 모니터링 끝내려면
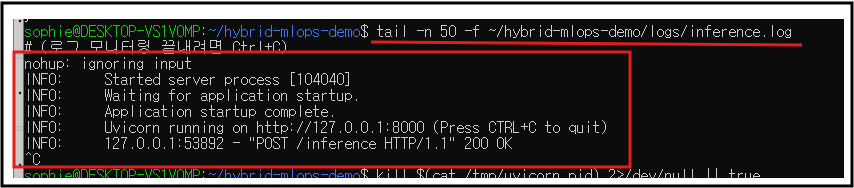
2-4) 서버 중지(정리)
kill $(cat /tmp/uvicorn.pid) 2>/dev/null || true
rm -f /tmp/uvicorn.pid

위까지 정상 동작하면, 로컬 요청/응답/로그가 모두 OK입니다.
이제 Ray Serve로 넘어가도 돼요.
3) Ray Serve로 서비스 올리기(포트 8001)
Ray 최신 API에 맞춰 route_prefix는 serve.run에서 지정합니다.
# 코드 생성/교체
cat > ~/hybrid-mlops-demo/ray_inference/serve_app.py <<'PY'
from ray import serve
from fastapi import FastAPI
import time
app = FastAPI()
@serve.deployment
@serve.ingress(app)
class InferenceService:
def __init__(self):
time.sleep(0.3) # (실전이라면 모델 로드)
@app.post("/")
def infer(self, payload: dict):
time.sleep(0.5) # 추론 지연 시뮬
return {"prediction": "vehicle", "confidence": 0.973}
if __name__ == "__main__":
# 포트 8001에 바인딩
serve.start(http_options={"host": "127.0.0.1", "port": 8001})
# 라우트 프리픽스 지정
serve.run(InferenceService.bind(), route_prefix="/inference")
PY

3-1) 실행(백그라운드)
# 혹시 모를 잔여 세션/포트 정리
ray stop --force 2>/dev/null || true
fuser -k 8001/tcp 2>/dev/null || true
# Ray Serve 앱 백그라운드 실행
nohup python3 ~/hybrid-mlops-demo/ray_inference/serve_app.py \\
> ~/hybrid-mlops-demo/logs/ray_serve.log 2>&1 & echo $! > /tmp/rayserve.pid
# 확인: PID 출력
cat /tmp/rayserve.pid
3-2) 호출 확인 (8001)
curl -sS -X POST <http://127.0.0.1:8001/inference> \\
-H 'Content-Type: application/json' \\
-d '{"image":"frame001.jpg"}' | jq .
계속 나에게 왜그러는건데.... 너 때문에 우분투 포털만 몇개 킨줄 아냐?
) 먼저 왜 죽었는지 로그 확인

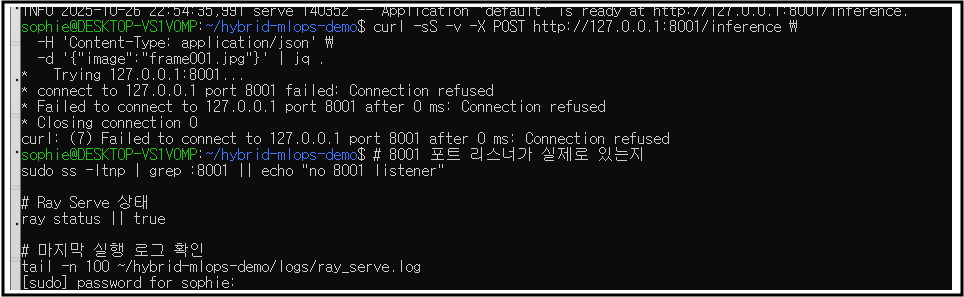

3-3) Ray 로그 확인........
# Ray가 제대로 떴다면 세션 로그 디렉토리가 생깁니다
ls -1 ~/ray/session_latest/logs | head
tail -f ~/hybrid-mlops-demo/logs/ray_serve.log
# (끝내려면 Ctrl+C)
3-4) 중지.....
kill $(cat /tmp/rayserve.pid) 2>/dev/null || true
rm -f /tmp/rayserve.pid
ray stop --force 2>/dev/null || true
다음은...?? Grafana/Loki로 로그 시각화
Promtail → Loki → Grafana로 받아보기 까지하면 모니터링 마스터 ~
https://github.com/daeun-ops/hybrid-mlops-demo
'DevOps' 카테고리의 다른 글
| [MLOps] hybird-mlops-demo 실행 순서 feat. 자꾸 까먹어서 내가보려고 작성한 글 (0) | 2025.10.28 |
|---|---|
| [MLOps]Ray Serve GPU 자동 감지 + Dockerize + Compose (0) | 2025.10.27 |
| [MlOps] Airflow 학습 DAG부터 Ray Serve 추론, Minikube까지 (0) | 2025.10.26 |
| [MlOps] Local MLOps 실습 환경 구축 (Airflow + MLflow) (0) | 2025.10.26 |
| [MLOps] RunPod 사용하여 A-LLMRec 모델 훈련 및 Inference 테스트 + colab pro+ 비용 및 성능 분석 (2) | 2024.11.26 |