[MLOps] RunPod 사용하여 A-LLMRec 모델 훈련 및 Inference 테스트 + colab pro+ 비용 및 성능 분석
목차
- Introduction
- 학습환경
- 1차시도 (1차시도 실패원인)
- 2차시도 (1단계 ~ 7단계)
- RunPod / Colab pro+ 가격 및 성능 비교
Introduction
테스트 내용을 공유하기에 앞서...
A-LLMRec는 사람들이 좋아할 만한 콘텐츠(영화, 책, 상품 등)를 더 잘 추천해주는 새로운 기술이다.
이 기술은 인공지능 언어 모델(LLM)과 기존 추천 시스템(사용자 데이터로 취향을 분석하는 시스템)을 합친 것입니다.
쉽게 말해, 기존 추천 시스템의 강점에 더해 인공지능 언어 모델의 똑똑함을 활용해서 더 정확하고, 다양한 상황에서도 잘 작동하도록 만든 것이다.
예를 들어
- 기존 사용자이미 데이터를 많이 가진 사용자에게 더 잘 맞는 추천
- 새로운 사용자 데이터를 거의 모으지 못한 새로운 사용자에게도 적절한 추천
- 적은 정보 정보가 부족해도 괜찮습니다. 적은 데이터만으로도 학습하고 추천
- 여러 분야 다른 종류의 콘텐츠(영화와 책 등)를 넘나들며 추천
결론적으로, A-LLMRec는 다양한 상황에서 똑똑하고 유연하게 작동하는 추천 시스템이다. 이 기술은 최신 연구로 인정받아 KDD 2024라는 큰 학회에서 발표되었고, 관련 코드도 공개되었다. 해당 오픈소스를 참고하면 좋을 것이다.
학습환경
학습 환경은 RunPod을 사용하여 진행하였다. Colab은 오랜시간 학습을 진행하면 런타임이 끊기는 에러가 발생하는 등등 정말 어려운 문제가 많았다. 그 와중에 RunPod이라는 새로운 클라우드를 발견했는데 가성비가 나쁘지 않은 것 같아 바로RunPod으로 학습을 진행했다.
내가 선택한 RunPod 사양은 아래와 같다.
비용적으로도 시간적으로도 굉장히 효율적인 RunPod은 해당 링크를 참고하면된다.
| • GPU사양: H100 PCIe ($2.69/h) • storage type: volume ($02.0/GB/month) • cloud type: Secure Cloud |
1차 시도
- 테스트 주제 1차: A-LLMRec 모델의 Phase 2 훈련 및 Inference 테스트
- 베이스 모델: OPT (Open Pre-trained Transformer)
- 사용한 데이터 정보: All_Beauty 카테고리의 전처리가 되지않은 추천 데이터셋

실패 원인: Phase 2 훈련 진행 중 cuBLAS API 오류 발생
- 모델 훈련 도중 cuBLAS API와 관련된 오류가 발생하였으며, 이는 GPU 자원과의 메모리 부족으로 인한 것으로 추정됨. 해당 오류는 모델의 효율적인 훈련이 불가함.
2차 진행 보완사항
- 사용한 데이터셋은 All_Beauty.jsonl.gz로, Amazon의 All Beauty 카테고리에서 수집된 리뷰 데이터이다. 이 데이터는 추천 시스템의 학습을 위해 적절히 전처리되어야함.
- 80기가의 메모리를 가진 환경에서 훈련을 진행했으나, 메모리 부족으로 인해 학습이 제대로 이루어지지 않았음. 모델의 복잡성과 데이터셋의 크기가 원인으로 작용한 것으로 추측.
- 데이터 전처리 작업을 원활하게 진행하기 위해 추가적인 코드 작업이 필요하며 데이터 로딩 및 처리 방식을 최적화하고, 메모리 관리에 유의하여 새로운 코드 구현 작업 필요
2차 시도
1차 시도에서 데이터 전처리를 진행하지 않아 기존 A100보다 좋은 성능이였음에도 불구하고 처참히 학습에 실패하였다.
데이터 전처리를 완료한 후 다시 학습에 시도하였다. 진행과정은 아래와 같다.
1단계 전처리 데이터 다운로드
소요시간 : 24/10/22 14:50 ~ 15:00
### 파이썬 콘솔
<https://drive.google.com/file/d/1cvBvBR25vspJyrfYiw9Yvuy-oDHB_9xW/view?usp=sharing>
1cvBvBR25vspJyrfYiw9Yvuy-oDHB_9xW
<https://drive.google.com/uc?id=1cvBvBR25vspJyrfYiw9Yvuy-oDHB_9xW>
다운시도
!pip install gdown
!gdown <https://drive.google.com/uc?id=1cvBvBR25vspJyrfYiw9Yvuy-oDHB_9xW>
안될경우
!pip install --upgrade --no-cache-dir gdown
2단계 파일 압축 해제
2-1
apt-get update

2-2
apt-get install unzip

3단계 상품에 대한 Titles/ Descriptions Summarizing
- Titles 요약 시간 (30분 소요)
- Descriptions 요약 시간 (4시간 소요)
- 오래 걸린이유 : ChatGPT 요청이 많아지면 속도 제한 걸림
3-1
cd ../../
pip install -r ori_requirements.txt
3-2
#경로 이동
cd /workspace/unzipped/A-LLMRec-20241022\\ 1st/pre_train/sasrec/
# 데이터 전처리 실행
python main.py --device=cuda --dataset All_Beauty

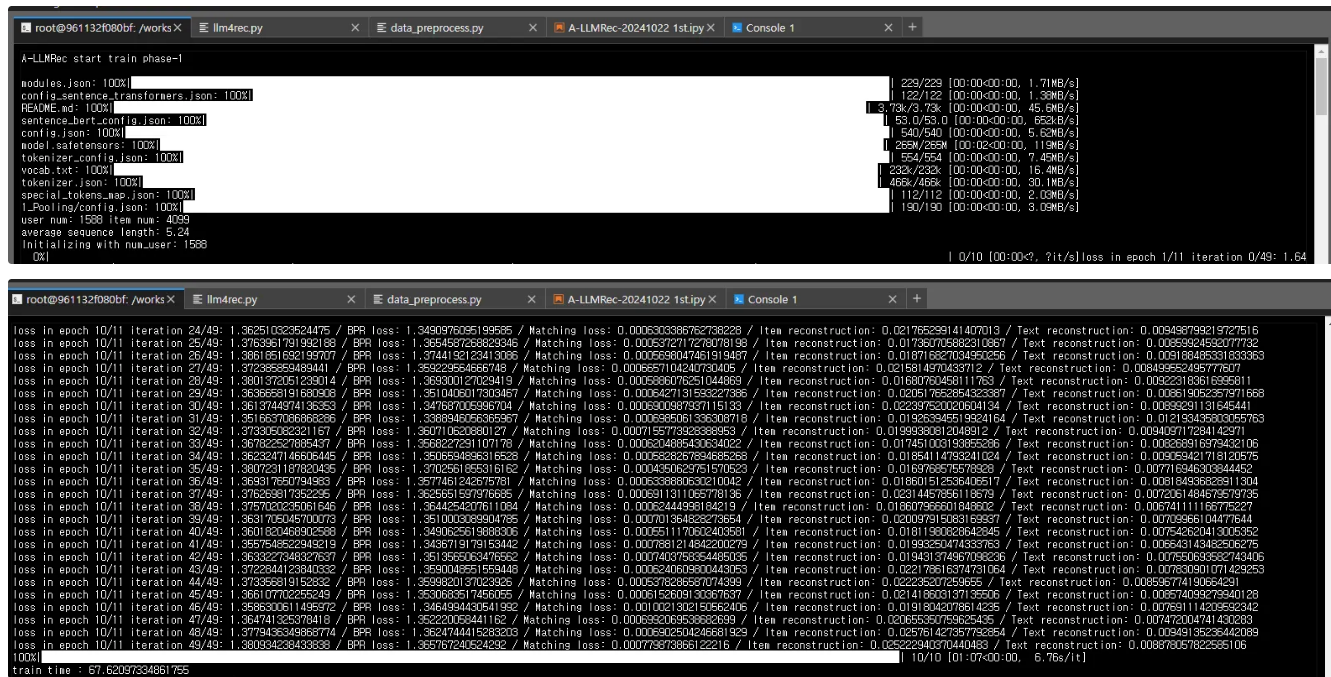
4단계 A-LLMRec 부분 스테이지 1 학습
train time : 69.97977757453918
python [main.py](<http://main.py/>) --pretrain_stage1 --rec_pre_trained_data All_Beauty
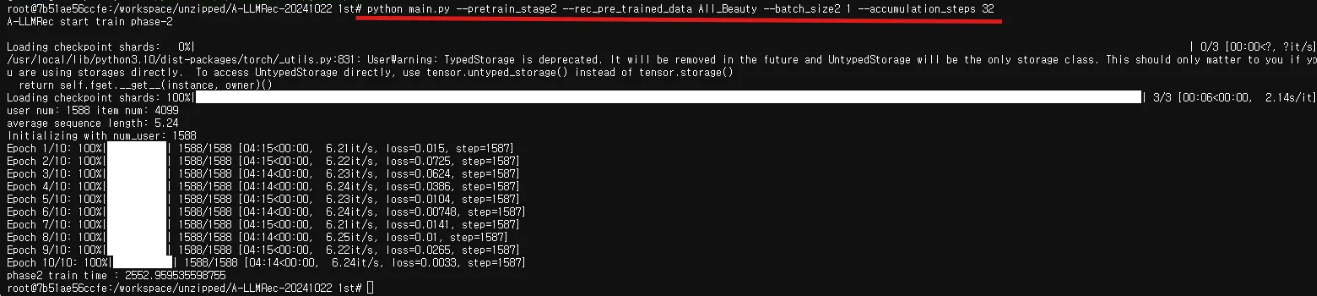
5단계 A-LLMRec 부분 스테이지 2 학습
phase2 train time : 2552.959535598755
python main.py --pretrain_stage2 --rec_pre_trained_data All_Beauty
스테이지2 트러블슈팅
#해당 Error 발생
OSError: [Errno 28] No space left on device

해결 방법 : https://blog.runpod.io/avoid-errors-by-s/
Avoid Errors By Selecting The Proper Resources For Your Pod
RunPod instances are billed at a rate commensurate with the resources given to them. Naturally, an A100 requires more infrastructure to power and support it than, say, an RTX 3070, which explains why the A100 is at a premium in comparison. While the speed
blog.runpod.io
Container Disk 20 → 40
Volume Disk 20 → 60

용량을 늘리고 다시 스테이지2를 실행했지만 해당 에러 발생

The `load_in_4bit` and `load_in_8bit` arguments are deprecated and will be removed in the future versions. Please, pass a `BitsAndBytesConfig` object in `quantization_config` argument instead.
Loading checkpoint shards: 0%| | 0/3 [00:00<?, ?it/s]/usr/local/lib/python3.10/dist-packages/torch/_utils.py:831: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
return self.fget.__get__(instance, owner)()
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:06<00:00, 2.13s/it]
user num: 1588 item num: 4099
average sequence length: 5.24
Initializing with num_user: 1588
Epoch 1/10: 0%| | 0/1588 [00:00<?, ?it/s] /usr/local/lib/python3.10/dist-packages/bitsandbytes/autograd/_functions.py:316: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantization
warnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
cuBLAS API failed with status 15
A: torch.Size([321, 5120]), B: torch.Size([5120, 5120]), C: (321, 5120); (lda, ldb, ldc): (c_int(10272), c_int(163840), c_int(10272)); (m, n, k): (c_int(321), c_int(5120), c_int(5120))
Epoch 1/10: 0%| | 0/1588 [00:00<?, ?it/s]
Exception: cublasLt ran into an error!
코드 변경 후 다시 스테이지2 실행
load_in_8bit=False,

성공.
6단계 답변 추론
소요시간 : 08:09<00:00
#답변 추론 -> 추론결과 : recommendation_output.txt
python main.py --inference --rec_pre_trained_data All_Beauty
7단계 평가
python eval.py
7개의 단계를 걸쳐서 A-LLMRec의 모델 학습을 성공적으로 마쳤다.
RunPod / Colab pro+ 가격 및 성능 비교
| Colab pro+ (A100) | RunPod (H100) | |
| 스테이지1 | 2분 | 1분 9초 |
| 스테이지2⭐ | 5시간 40분 * 메모리 부족 문제 발생 (RAM 40GB) | 42분 32초 |
| 답변 추론 | 11분 42초 | 8분 9초 |
| 총 시간 | 5시간 53분 42초 | 4시간 51분 50초 |
| 비용 | 99.98 달러 (정기결제+1회 추가충전) | 68.33 달러 (전처리 시간 포함 금액) |
| 비고 | A100하나만 사용했을 때 이며 추가로 사용된 서버 자원은 없음. |
데이터 전처리는 학습환경과 무관하게 단순히 GPT 자체 속도 제한이 걸려서 4시간이 걸린 것임 |
스테이지 1, 2 (A-LLMRec) 모델 학습과 답변 추론면에서 진행 효율성이 높음. 특히, 중요한 모델 학습 부분에서 약 4배 정도 속도가 빨랐음. (시간 효율성이 좋음)
- 데이터 전처리 시, GPT-4o-mini 요청 시 속도 리밋이 걸려서 4시간 정도 소요됨.